Scalable software architecture refers to the structural capability of a system to expand in capacity, functionality, data volume, and workload intensity while maintaining stability, reliability, usability, and predictable performance behavior. Instead of treating scalability as a late-stage optimization, advanced engineering teams treat it as a core architectural discipline that influences design, infrastructure strategy, deployment pipelines, data modeling, communication protocols, and system evolution over time. A scalable architecture is designed to grow gradually rather than break suddenly as demand increases, meaning the system tolerates high-traffic surges, distributed workloads, geographic expansion, and continuously increasing feature complexity without requiring complete redesign. Scalability ensures that the system remains operational, efficient, cost-controlled, and analyzable even when millions of concurrent users interact with it or when data stretches across regions and services. It supports modular evolution, backward-compatible changes, elasticity, and failure recovery mechanisms that prevent cascading breakdowns. Scalable architecture also adapts to unpredictable workloads such as seasonal spikes, promotional events, analytics bursts, or real-time streaming loads where demand changes instantaneously. Instead of scaling blindly, the architecture scales strategically with observability metrics, threshold monitoring, automated decision logic, and controlled provisioning behavior. In essence, scalable architecture is not only about growth it is about sustainable, intelligent, testable, and future-proof system expansion.
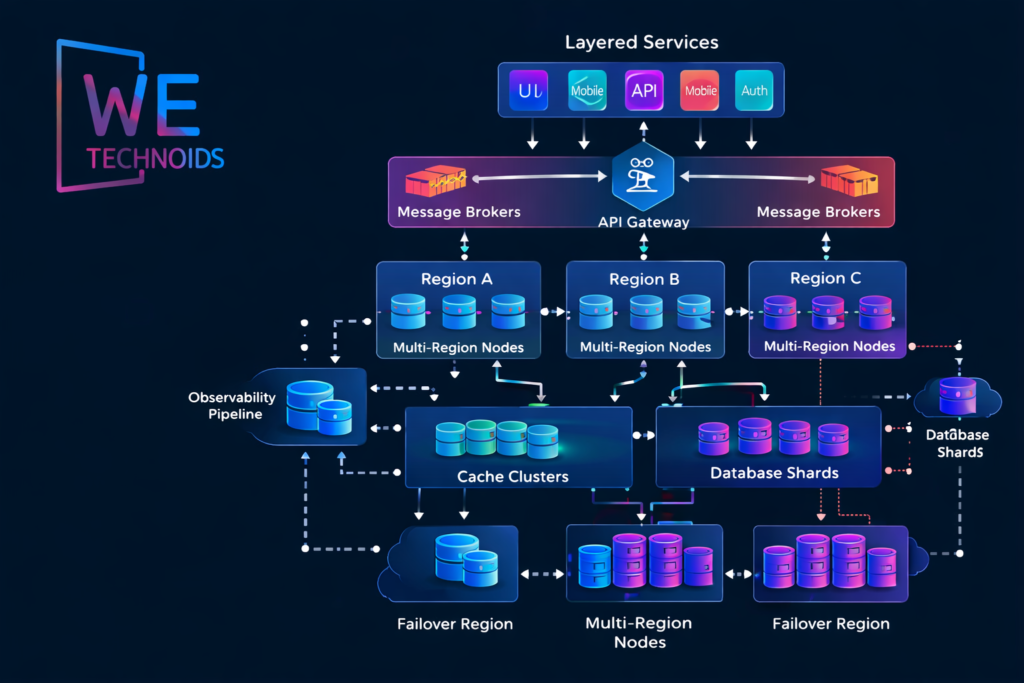
Architectural Layers in Scalable Systems
A scalable architecture is composed of multiple layered components that each have independent growth boundaries, operational responsibilities, and scaling triggers. The presentation layer manages client interactions and must be able to scale across multiple front-end delivery nodes, CDNs, and edge caches to minimize latency. The application service layer contains business logic and often runs as stateless microservices or modularized monolith segments that can scale horizontally. The integration layer manages API gateways, service registries, service mesh communication, routing rules, authentication layers, and circuit breakers that protect against cascading failures. The data layer consists of relational databases, NoSQL systems, time-series stores, graph databases, and distributed file storage systems each selected based on workload patterns rather than convenience. The processing layer supports background workers, batch pipelines, streaming processors, and asynchronous event consumers that handle resource-heavy computations without blocking user transactions. An observability layer monitors logs, traces, metrics, and incident alerts, while the orchestration layer manages container scheduling, deployment rollouts, scaling thresholds, and recovery automation. Each layer must scale independently while still preserving global system consistency, operational clarity, and architectural coherence.
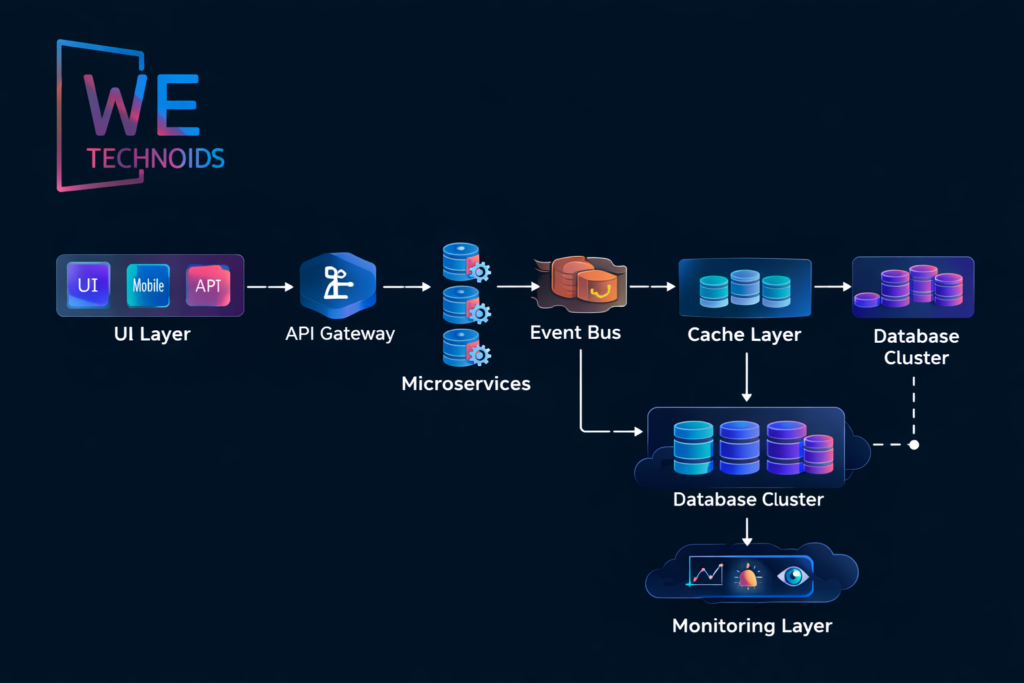
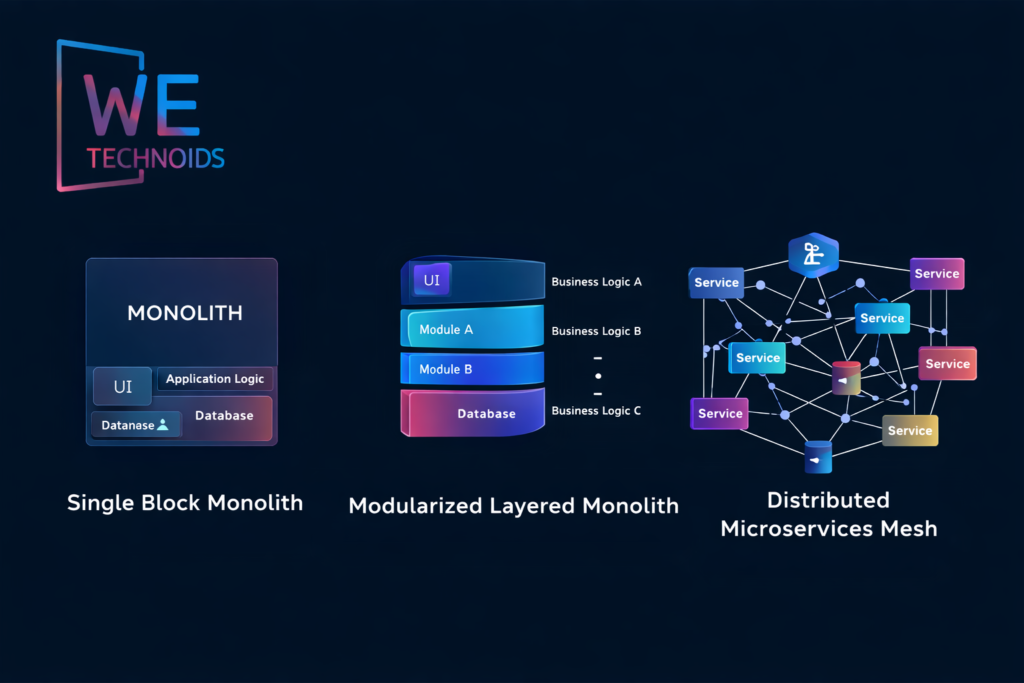
Monolithic vs Microservices vs Modular Monolith
A monolithic architecture centralizes all business functionality, databases, and user interactions inside a single deployable unit, which simplifies development early but becomes extremely difficult to scale independently because every performance issue forces the entire system to scale as one block. Microservices architecture decomposes systems into independently deployable services, each owning a bounded domain and separate data model, which improves scalability, resilience, and development speed but introduces higher operational complexity, network latency concerns, version drift risks, and distributed debugging challenges. A modular monolith sits between both extremes, where the system remains in a single deployable unit but is internally structured into strongly separated modules with clear domain boundaries, allowing teams to gradually evolve toward microservices only when scaling pressure demands it. Real-world organizations rarely jump directly to microservices instead, they evolve through modular decomposition, domain isolation, and observability-driven migration. The best architecture is not the most distributed one it is the one that scales predictably with the lowest operational burden and maximum business value alignment.
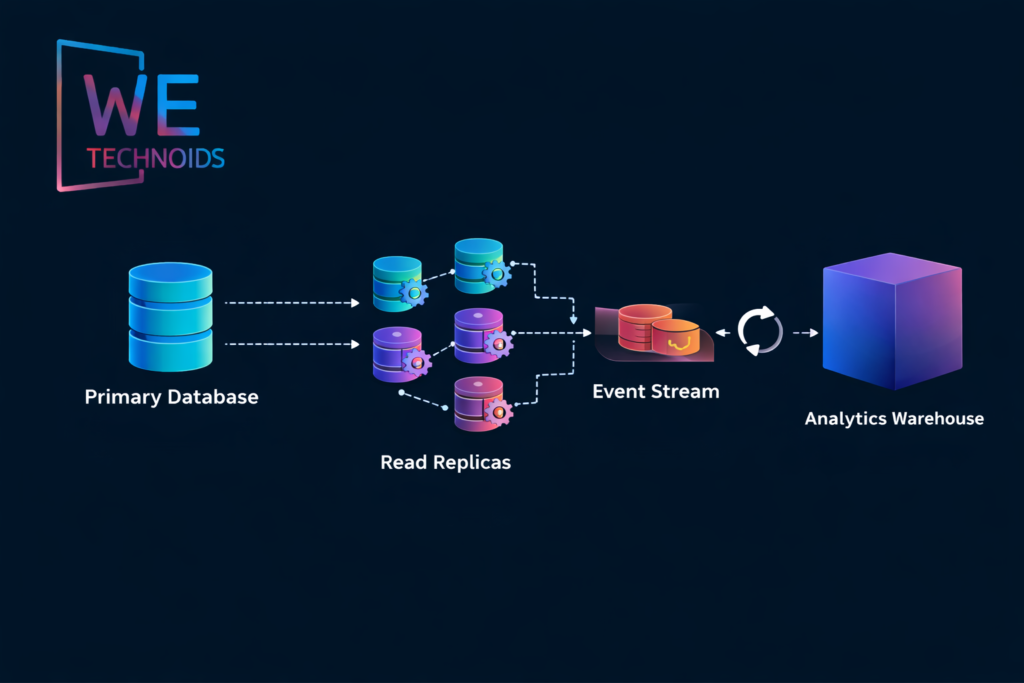
Scalable Data Architecture
Data scalability is often the primary factor that determines whether an architecture can scale or collapses under pressure. Traditional relational databases scale vertically but struggle when write loads, global replication, or analytics pipelines intensify. Distributed architectures introduce read replicas, sharding, partitioning, write-ahead logs, and event streaming to separate transactional workloads from analytical ones. Systems requiring strong consistency rely on ACID guarantees, whereas high-availability distributed systems adopt BASE and eventual consistency models to tolerate network partitions and regional replication delay. Architectural choices must align with business semantics financial transactions require strict ordering and accuracy, while social feeds tolerate eventual synchronization. CQRS (Command Query Responsibility Segregation) separates read and write workloads to improve performance at scale, while event sourcing maintains immutable event logs that reconstruct historical state on demand. Every data scaling decision introduces trade-offs involving latency, correctness, cost, availability, and operational risk so scalable architecture must treat data design as a first-class engineering discipline rather than a storage convenience decision.
Advanced Scaling Strategies
Horizontal Scaling with Stateless Services
Horizontal scaling distributes workloads across multiple nodes, containers, or regions, allowing the system to expand without increasing risk. Stateless services make this strategy effective because any instance can handle any request without dependency on local session storage. When properly designed, failed nodes are simply replaced, and traffic reroutes automatically.
Functional Scaling through Domain Decomposition
Instead of scaling everything, scalable systems identify high-traffic domains such as authentication, billing, search, or analytics and scale them independently. Domain-driven design ensures growth follows business boundaries rather than technical splitting, producing cleaner, predictable scalability trajectories.
Asynchronous & Event-Driven Processing
Long-running tasks move to background workers, message queues, or streaming pipelines. This prevents user operations from blocking, improves throughput capacity, and protects systems from overload under burst load conditions.
Fully Explained Architectural Insights
Scalability must be treated as a core engineering discipline rather than something added after systems start experiencing failure or capacity breakdowns. Systems that scale successfully are intentionally designed with future growth in mind, meaning engineers study workload patterns, usage behaviors, and data expansion trends before bottlenecks appear. Reactive optimization leads to instability, whereas proactive scalability planning ensures systems evolve smoothly over time.
- Performance tuning may temporarily improve response speed, but it does not guarantee system growth or long-term stability. Scalability focuses on whether a system can handle increasing users, traffic, regions, services, and data volume without architectural collapse. A system can perform well at small scale but still fail during rapid expansion if it lacks elasticity, decoupling, or distributed load capability meaning scalability determines long-term survivability rather than short-term performance gains.
- Distributed systems introduce new forms of complexity and failure risks such as latency variations, partial outages, clock synchronization issues, race conditions, and partition tolerance challenges. These risks cannot be solved through hardware upgrades or server replication alone. Instead, resilience mechanisms like circuit breakers, retries, failover paths, and fault-containment zones must be built into the architecture from the start to prevent cascading failures across the ecosystem.
Data architecture decisions influence scalability more than compute power or server resources. Most large-scale failures arise from centralized databases, synchronous write dependencies, non-partitioned datasets, and overloaded transactional bottlenecks. Sustainable scalability depends on strategies like sharding, replication, event streaming, caching tiers, read-write separation, and asynchronous pipelines because data flow and storage pressure define true scaling limits.
- Real scalability emerges from controlled expansion and graceful failure behavior, not unlimited growth. Systems must implement automation, rate limiting, load shedding, back-pressure mechanisms, and degradation strategies that allow partial functionality instead of total service collapse. Defined scaling boundaries ensure capacity increases remain predictable, sustainable, and aligned with architectural constraints rather than chaotic or uncontrolled.
Systems must scale not only at the technical level, but also at the operational and organizational level. As architectures grow, deployment pipelines, monitoring systems, incident workflows, engineering ownership models, and communication structures must also mature. If organizational processes remain static while infrastructure expands, instability increases meaning true scalability requires technology, operations, and teams to evolve together.
Real-World Enterprise Scaling Scenarios
E-Commerce High-Traffic Sales Event
During peak campaigns such as seasonal sales or promotional events, e-commerce platforms experience massive surge traffic where millions of users browse products, add items to carts, and attempt to check out simultaneously. Scaling the entire platform uniformly is inefficient instead, cart, inventory, pricing, catalog browsing, and checkout services are isolated into independent scaling domains. Read-heavy operations such as catalog browsing run primarily on cache and distributed replicas, reducing database stress. Checkout operations remain strongly consistent and often rely on transactional isolation, while asynchronous stock updates prevent database locks from delaying user orders. Queue-based order confirmation protects payment gateways and downstream services from overload by smoothing burst traffic into controlled processing streams. Failover regions remain ready to absorb sudden load shifts, and monitoring pipelines detect saturation thresholds before failures occur. This approach not only preserves performance during traffic spikes but prevents full-system outage one overloaded module cannot bring down the entire platform because fault isolation boundaries already exist.
Major Scalability Challenges & Failure Risks
Real scalability challenges rarely come from raw code execution they emerge from distributed coordination complexity, untested scale thresholds, and misunderstood system behavior under stress. Large-scale systems must cope with network latency, packet loss, replica synchronization lag, clock drift between nodes, memory pressure under load, and cascading retry failures when dependent services slow down. Circuit breakers prevent one failing service from triggering a full-system cascade, but poor timeout configuration can convert temporary slowdowns into global outages. Unbounded message queues may lead to backlog buildup that surfaces hours later as delayed failure. Configuration drift across environments introduces unpredictable performance differences that are difficult to diagnose. Cold start delays in serverless systems create inconsistent latency during sudden traffic bursts. The most dangerous failures occur when systems behave correctly at low traffic but collapse under sustained high-load because capacity assumptions were never verified in production-like testing conditions. Scalable architecture must therefore treat risk as an engineering dimension not an operational afterthought.
Scalability Testing & Reliability Engineering
Reliability-driven teams validate scaling behavior through structured engineering experiments rather than assumptions or synthetic benchmarks. Load testing evaluates how latency, throughput, and error rates behave when traffic gradually increases, while soak testing measures stability during long-running sustained load conditions. Chaos testing intentionally introduces failure events such as node crashes, database outages, or network partitions to verify whether the system degrades gracefully or collapses. Failure-injection testing validates retry handling, back-pressure behavior, and message idempotency across asynchronous pipelines. Shadow traffic testing sends real-world traffic to parallel systems to observe scaling performance without risking user impact. Observability platforms track saturation thresholds, tail latency distribution, resource utilization curves, and incident correlation patterns to refine scaling decisions based on evidence rather than estimates. Through continuous reliability validation, systems evolve from fragile, assumption-driven models into resilient, predictable architectures capable of supporting long-term operational growth.
Conclusion
Scalable software architecture is not an add-on feature but a systemic design philosophy that shapes how systems evolve, recover, adapt, expand, and survive real-world computational stress. True scalability integrates distributed design, domain-aware data modeling, resilient communication, asynchronous pipelines, operational automation, and long-term architectural foresight. Organizations that treat scalability as an engineering foundation rather than a late-stage patch build digital platforms capable of sustaining growth, innovation, and reliability across years of evolutionary expansion.