Large Language Models (LLMs) are among the most transformative advancements in artificial intelligence, capable of understanding, interpreting, and generating human-like language. Unlike traditional rule-based or statistical NLP systems, LLMs rely on neural network architectures to model the probability distributions of language across enormous datasets. They analyze patterns across billions of words and create internal representations that capture meaning, context, syntax, semantics, and relationships between concepts. These models can perform tasks ranging from question-answering and summarization to code generation and creative writing, demonstrating flexible and context-aware reasoning. The foundation of LLMs lies in Transformer architectures, which use self-attention mechanisms to process text sequences in parallel while maintaining an understanding of long-range dependencies. By learning from massive text corpora, LLMs build latent knowledge representations, enabling them to generate contextually coherent outputs rather than simply retrieving pre-existing text. Fine-tuning, reinforcement learning from human feedback, and alignment techniques ensure that outputs are helpful, safe, and consistent. LLMs have revolutionized industries like education, healthcare, finance, and software development by automating language-intensive tasks, providing real-time assistance, and scaling human knowledge across digital platforms. This article explores how LLMs work in depth, covering tokenization, embeddings, Transformer architecture, training strategies, real-world applications, limitations, and best practices for deployment.
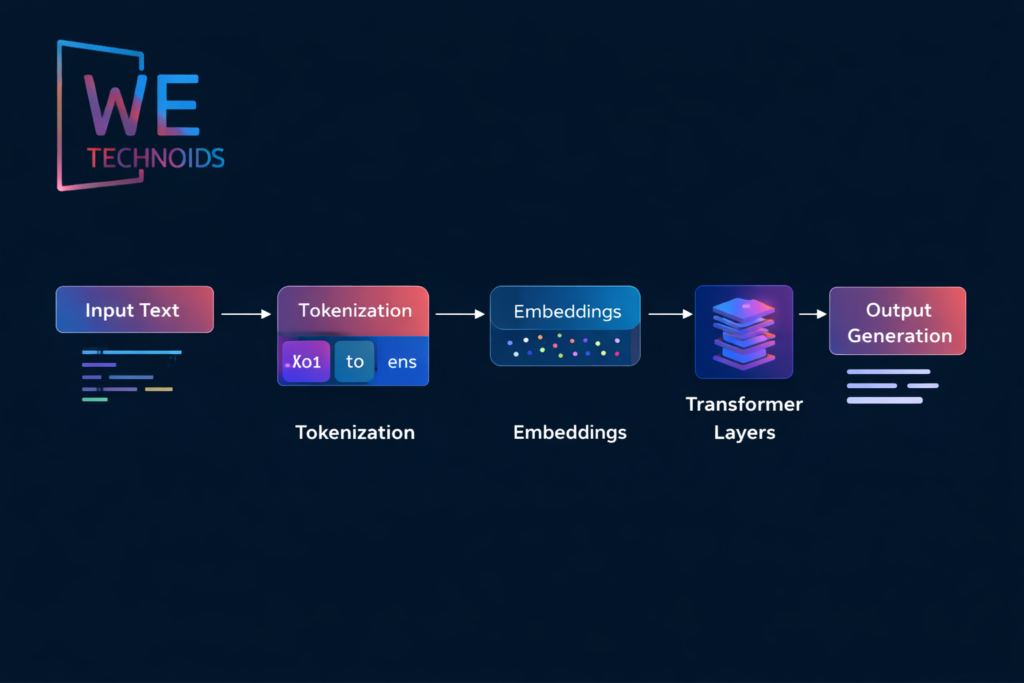
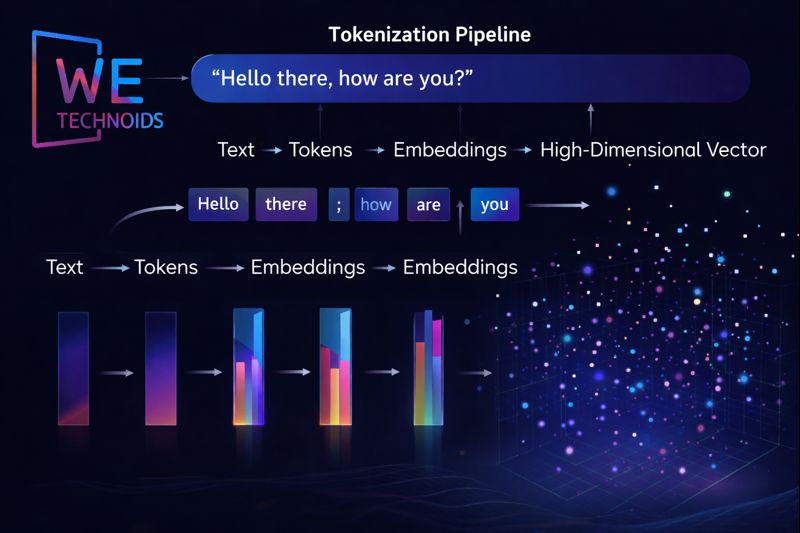
Tokenization & Embeddings - How LLMs Represent Text
LLMs do not process text as raw words; instead, they first convert text into tokens, which are subword units or characters that represent meaningful fragments of language. Tokenization allows the model to handle rare words, compound phrases, and multiple languages efficiently. Each token is then transformed into a high-dimensional vector called an embedding, which captures semantic meaning, syntactic role, and contextual relationships. Words or phrases with similar meanings cluster closely in embedding space, enabling analogies, paraphrasing, and concept association. These embeddings serve as the input to Transformer layers, where contextual meaning is refined through self-attention and multi-layer processing. Embeddings are learned during training and updated across billions of parameters, allowing the model to generalize patterns beyond the exact text it has seen. This distributed representation approach ensures that LLMs understand language probabilistically rather than memorizing phrases verbatim, providing flexibility in generation, reasoning, and inference.
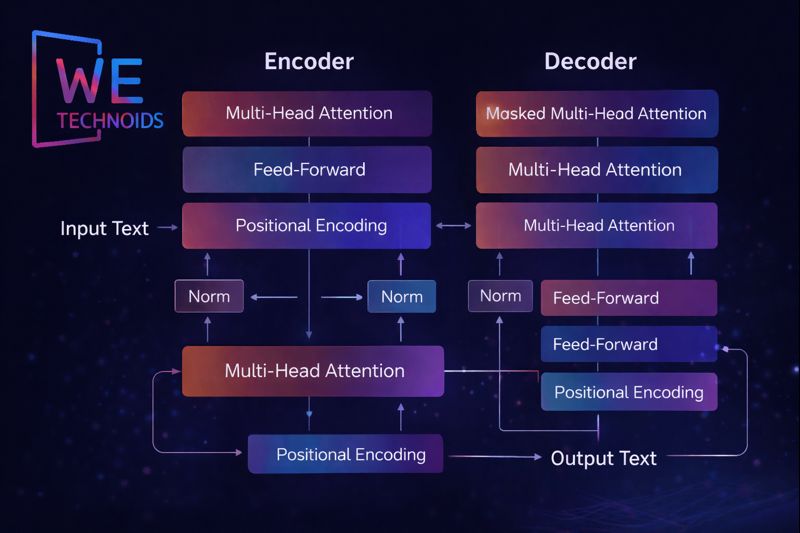
Transformer Architecture & Self-Attention
The Transformer architecture enables LLMs to process long sequences efficiently and accurately. Its key innovation is the self-attention mechanism, which allows every token in a sequence to interact with every other token simultaneously. Attention weights dynamically determine the importance of each token relative to others, enabling the model to capture relationships like subject-verb agreement, pronoun references, and contextual meaning across long paragraphs. Multi-head attention further enhances this capability by evaluating multiple aspects of context in parallel, such as syntax, semantics, and positional relevance. Unlike older RNNs and LSTMs, Transformers process tokens in parallel rather than sequentially, dramatically improving computational efficiency and scalability. Positional encodings allow the model to preserve the order of words, maintaining coherence in generation. The stacked Transformer layers, consisting of attention and feed-forward blocks, create deep representations of language that allow LLMs to perform reasoning, summarization, translation, and creative generation tasks at scale.
Training Pipeline of LLMs
Pre-Training
Pre-training is the foundation of the LLM training pipeline and represents the stage where the model learns the core structure and behavior of human language at massive scale. In this phase, the model is exposed to enormous datasets containing books, research papers, web documents, programming code, encyclopedia content, and conversational text gathered from diverse domains and writing styles. Instead of being explicitly told what is right or wrong, the model learns in an unsupervised manner by predicting the next token in billions of sentences or reconstructing missing parts of text sequences. Through this repeated process, the LLM learns grammar, syntax, semantics, narrative flow, contextual relationships, logical connections between concepts, and even patterns of reasoning embedded in natural language. The model does not memorize sentences rather, it builds probabilistic understanding of how words relate to one another in different contexts, which allows it to generalize to new content. Pre-training also helps the model recognize long-range dependencies in language, such as cause-and-effect reasoning, discourse continuity, argument structure, and sentence-level coherence. By the end of this phase, the model develops a broad, general-purpose comprehension of human communication, but its knowledge remains unspecialized and not yet safety-aligned, which makes the later stages of refinement essential.
Fine-Tuning
Fine-tuning takes the broadly trained language model from the pre-training phase and adapts it to specific domains, applications, or professional use-cases where accuracy, relevance, and controlled behavior are required. During this stage, the model is trained on curated, high-quality datasets that may include medical literature, legal documents, programming repositories, academic text, industry reports, or enterprise communication logs, depending on the intended application. Fine-tuning reshapes the model’s parameters so that it can understand specialized terminology, structured reasoning styles, regulatory language constraints, and the practical expectations associated with real-world problem-solving. For example, a healthcare-focused fine-tuned model learns to respond using clinical clarity and factual caution, while a coding-oriented model improves at syntax understanding, debugging reasoning, and code generation accuracy. This process reduces ambiguity, enhances precision, and transforms a general LLM into a more reliable task-aware assistant. Fine-tuning also improves instruction-following behavior, contextual awareness, and response consistency in professional environments. However, even after fine-tuning, the model may still produce outputs that are verbose, misaligned, or lacking ethical filtering which is why reinforcement and alignment steps are introduced next.
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from Human Feedback (RLHF) represents a major innovation in modern LLM training because it integrates real human judgment into how the model learns desirable and appropriate behaviors. In this stage, human evaluators review multiple responses generated by the model for the same prompt and then rank them based on clarity, helpfulness, tone, factual strength, safety considerations, and contextual appropriateness. These rankings are used to train a reward model that guides the LLM to prefer responses that align closely with human expectations rather than purely statistical likelihood. RLHF helps reduce hallucinations, irrelevant or overly-technical responses, and emotionally inappropriate output, while improving cooperative dialogue flow and natural conversation quality. It also encourages the model to communicate in a way that is more supportive, concise when necessary, and sensitive to user intent. This stage is not only about improving accuracy it also shapes personality, conversational style, politeness, and trustworthiness in interactive contexts. RLHF bridges the gap between raw computational intelligence and socially responsible communication, refining the model into a system that behaves more like a thoughtful digital assistant rather than a text-prediction engine.
Alignment
The alignment stage focuses on ensuring that the model behaves safely, ethically, and responsibly across cultures, industries, and sensitive use-cases. Alignment integrates policy constraints, fairness guidelines, harm-prevention rules, bias-mitigation strategies, and regulatory compliance standards into the model’s behavior. This process addresses risks arising from real-world data exposure, such as harmful stereotypes, misinformation patterns, security-sensitive instructions, or socially inappropriate content. Alignment frameworks define the boundaries of what the model should answer, where it should refuse, and how it should respond in ethically complex or safety-critical situations. It also includes iterative audits, safety evaluations, ethical review pipelines, and continuous monitoring to ensure the model remains consistent as new knowledge, risks, and usage environments emerge. Alignment is not a single training step it is an evolving discipline that adapts to legal standards, cultural diversity, responsible innovation principles, and societal expectations. The goal is to ensure that LLMs remain powerful, useful, respectful, and trustworthy, while minimizing harmful outcomes or unintended consequences in real-world deployments.
Reinforcement Learning from Human Feedback (RLHF)
Inference is the final stage of the LLM lifecycle where all previous training, fine-tuning, reinforcement learning, and alignment efforts come together in real-time user interaction. During inference, the model processes input prompts, interprets context across the conversation window, and generates text token-by-token based on probability distributions learned throughout training. The response is influenced simultaneously by pre-training knowledge, specialized fine-tuning, alignment policies, and RLHF-guided preferences. Advanced decoding strategies such as temperature control, nucleus sampling, and top-k filtering allow systems to balance creativity, determinism, and accuracy depending on application needs. Large-scale deployments use optimization techniques like quantization, batching, and model parallelism to reduce latency and compute cost while maintaining output quality. Inference transforms the model from a static trained network into a dynamic reasoning companion capable of answering questions, generating explanations, solving problems, writing content, assisting workflows, and supporting decision-making across industries. It is at this stage that users directly experience the full outcome of the LLM training pipeline as a functional, context-aware, and interactive AI system.

Key Architectural Insights
- LLMs model probabilistic language patterns, not fixed knowledge. Understanding emerges from distributed representations across billions of parameters.
- Attention mechanisms allow dynamic context weighting, capturing long-range dependencies and subtle semantic relationships in text.
- Embeddings encode word meaning, context, and positional information in high-dimensional vector space, enabling semantic similarity and reasoning.
- LLMs rely on Transformer layers with multi-head attention and feed-forward blocks, allowing parallel sequence processing and long-range contextual reasoning.
- Scaling laws indicate that increasing model size, dataset diversity, and training steps improves performance, but only when compute and data quality are sufficient.
- Fine-tuning, reinforcement learning, and alignment are necessary to ensure outputs are helpful, safe, and coherent, preventing hallucinations or unsafe generation.
- Real-world deployment requires efficient inference strategies, memory optimization, and hardware scaling to handle high throughput while minimizing latency.
Real-World Applications of LLMs
- E-Learning & Tutoring Systems
- Software Development & Automation
- Research & Knowledge Discovery
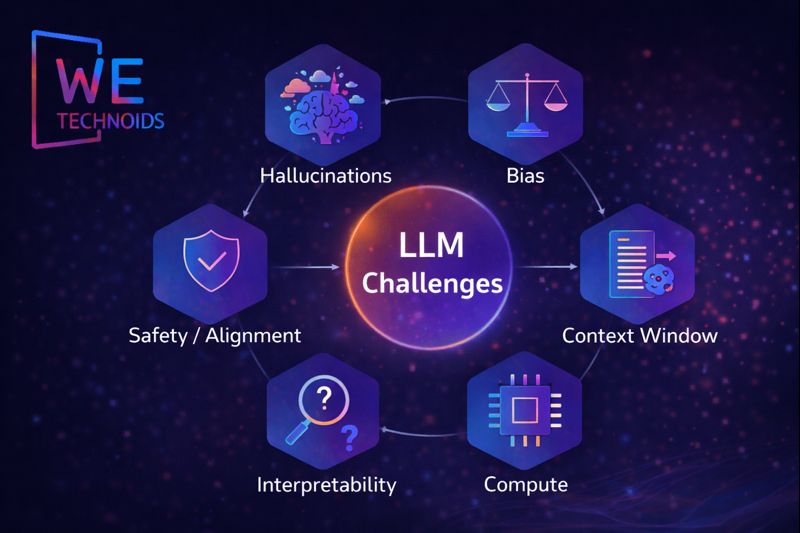
Challenges & Limitations of Large Language Models (LLMs)
Large Language Models (LLMs) have revolutionized natural language processing, but they are not without significant challenges and limitations that must be carefully managed in practice. One of the primary issues is hallucinations, where the model produces outputs that are plausible, coherent, and grammatically correct but factually incorrect or entirely fabricated. This occurs because LLMs generate text based on probabilistic patterns learned from their training data rather than verifying factual accuracy against an external knowledge source. Another major limitation is bias and ethical risks since LLMs are trained on vast datasets derived from human-generated content, they inevitably reflect societal biases, stereotypes, and cultural imbalances present in the data. Models can inadvertently produce outputs that are discriminatory, offensive, or reinforce harmful assumptions, requiring careful mitigation strategies. Context limitations also pose challenges, as LLMs operate within a fixed-length attention window; very long documents, complex arguments, or multi-step reasoning tasks can exceed the model’s memory capacity, resulting in degraded understanding or incomplete answers. LLMs are also extremely compute-intensive, demanding enormous GPU/TPU clusters, high memory bandwidth, and extended training cycles, which raises financial costs, energy consumption, and environmental impact. Furthermore, interpretability remains a critical limitation the internal decision-making process of billions of parameters is opaque, making it difficult to explain why a particular output was generated. Finally, safety and alignment present ongoing challenges, as developers must balance openness, creativity, and utility with ethical behavior, risk mitigation, and compliance with legal or societal norms. Each of these limitations highlights that while LLMs are powerful, they require careful design, monitoring, and human oversight to function reliably in real-world applications.
Evaluation & Continuous Improvement
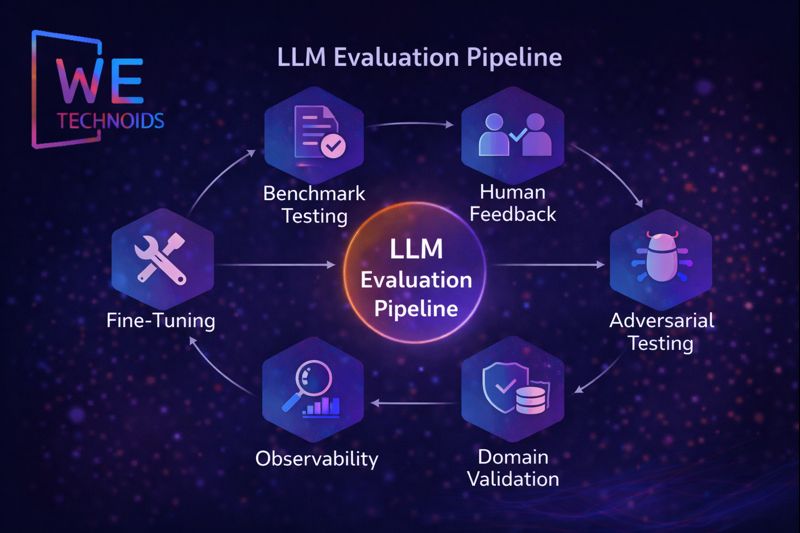
To ensure that LLMs remain effective, reliable, and safe, they undergo continuous evaluation and improvement throughout their lifecycle. Evaluation begins with standardized benchmark tests, which assess the model’s capabilities in reasoning, comprehension, creativity, summarization, translation, and domain-specific tasks. In addition, human feedback plays a crucial role: expert reviewers rate generated outputs for relevance, accuracy, clarity, and safety, guiding reinforcement learning processes like RLHF (Reinforcement Learning from Human Feedback). LLMs are also subjected to adversarial testing, where carefully crafted prompts are used to uncover vulnerabilities, hallucinations, or bias patterns, allowing engineers to strengthen the model’s robustness. Domain-specific validation ensures that outputs meet specialized knowledge requirements, such as medical recommendations, legal advice, or scientific research applications. Observability pipelines continuously track key metrics, including hallucination frequency, bias incidence, token latency, memory utilization, model drift over time, and throughput performance, providing actionable insights for improvement. Iterative retraining and fine-tuning help the model adapt to new knowledge, emerging terminology, and evolving linguistic patterns. In addition, ethical evaluation metrics and safety-alignment procedures are regularly updated to minimize harmful or unsafe outputs. Together, these evaluation strategies create a closed feedback loop, allowing LLMs to improve continuously, maintain user trust, and function as reliable, context-aware, and responsible AI systems capable of scaling to diverse real-world applications.
Conclusion
LLMs are not just advanced text generators; they represent a paradigm shift in AI, moving from deterministic, rule-based computation to probabilistic, context-aware, and reasoning-capable systems. By combining large-scale training, Transformer-based architectures, attention mechanisms, embeddings, and alignment techniques, LLMs perform sophisticated language tasks across industries. As research continues in areas such as memory, interpretability, safety, and efficiency, LLMs will become central to education, software development, research, communication, and human-machine collaboration at scale.